So I have been developing a product in my own spare time lately, it's called Tagbox. It's a bookmarking application similar to Zotero, Raindrop.io, or Pocket.
As the name of the application implies a bit, the application can categorizes each links using tags. This way, the user can search for links easily. Yeah, search functionality. That's when I thought: how do users search using tags?
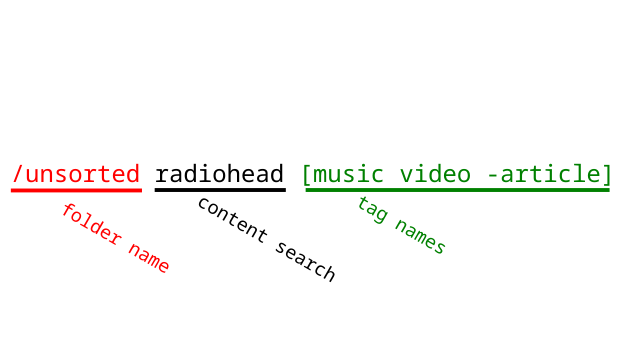
Of course, by typing the tags as search query. But then, my brain goes further: what if user want some logic in the search. For example, user wants to search for links that have the tags video and music but want to exclude the tag article? Hmmm.
That's when I thought: why not I make my own syntax for searching?
This is what I came up with:
Demo Using WASM
Here is the demo of the parser if you're curious.
So let's start implementing it. I will use Go for the language, as that is the language I'm using for Tagbox.
Rob Pike's talk about lexer
I will be following along a talk by Rob Pike's from more than a decade ago. Here is the video and here is the slides.
Setting some constants
Using the Iota feature from Go and additionally some type aliasing, we can define some constants that act like an "enum" for the type of value--like text, whitespace, end-of-file (EOF), folder name, etc.
type itemType int
type item struct {
typ itemType
val string
}
const (
itemError itemType = iota
itemEOF
itemWhitespace
itemText
itemFolderNameMeta
itemFolderNameIdentifier
itemContentSearchWords
itemTagsLeftMeta
itemTagsDivider
itemTagOperator
itemTagName
itemTagsRightMeta
)
We will also define some constant of characters like slash or bracket:
const whitespace = " "
const folderNameMeta = "/"
const tagsLeftMeta = "["
const tagsDivider = " "
const tagsRightMeta = "]"
const tagNegationOperator = "-"
const tagJoinOperator = "+"
const eof = -1
Lexer
Next, I will define a struct for lexer.
type lexer struct {
name string
input string
start int
pos int
width int
items []item
}
The struct contains the input string, position of the lexer is working on, and the result in the field items. Okay, I will admit--the field items was supposed to be a channel to enable concurrency like Rob Pike stated, but... I wasn't able to implement them, so for now I will choose the more naive method. Besides, I'm only lexing for relatively short search query, not designing a template engine for Go.
Methods for lexer
Next we will write some helpful methods for the lexer struct.
func (l *lexer) emit(t itemType) {
l.items = append(l.items, item{t, l.input[l.start:l.pos]})
l.start = l.pos
}
emit will append item that contains lexed string and the type to the result slice.
func (l *lexer) next() (r rune) {
if l.pos >= len(l.input) {
l.width = 0
return rune(eof)
}
r, l.width = utf8.DecodeRuneInString(l.input[l.pos:])
l.pos += l.width
return r
}
next will return the next character as rune type. It will also return eof constant if the position reached the end. This can be great for error handling
State machine
Turns out implementing state machines in Go is quite simple. The states are represented as a function. A lexer struct will be received as the argument of the function and will return the next state. If returns nil, then it's the end of the state machine.
type stateFn func(*lexer) stateFn
Running the state machine
Other method lexer has is run which will start the state machine. This will run a for loop until state machine returns nil.
func (l *lexer) run() {
for state := lexText; state != nil; {
state = state(l)
}
}
State function
Okay, prepare for the spaghetti code.
The state machine starts with lexText state, which means a plain text.
If the current position of the string starts with / (slash) it will mean the next state will be the symbol that starts before a folder name (the lexFolderNameMeta function which will be followed by lexFolderNameIdentifier).
However if the current position starts with [ (open square bracket) it will mean the next state will be tags.
func lexText(l *lexer) stateFn {
for {
if strings.HasPrefix(l.input[l.pos:], folderNameMeta) {
if l.pos > l.start {
l.emit(itemText)
}
return lexFolderNameMeta
}
if strings.HasPrefix(l.input[l.pos:], tagsLeftMeta) {
if l.pos > l.start {
l.emit(itemText)
}
return lexTagsLeftMeta
}
if l.next() == eof {
break
}
}
if l.pos > l.start {
l.emit(itemText)
}
l.emit(itemEOF)
return nil
}
func lexFolderNameMeta(l *lexer) stateFn {
l.pos++
l.emit(itemFolderNameMeta)
return lexFolderNameIdentifier
}
func lexFolderNameIdentifier(l *lexer) stateFn {
for {
if strings.HasPrefix(l.input[l.pos:], whitespace) {
l.emit(itemFolderNameIdentifier)
return lexText
}
r := l.next()
if r == eof {
break
}
}
l.emit(itemFolderNameIdentifier)
l.emit(itemEOF)
return nil
}
func lexTagsLeftMeta(l *lexer) stateFn {
l.pos++
l.emit(itemTagsLeftMeta)
return lexTagName
}
func lexTagName(l *lexer) stateFn {
for {
if strings.HasPrefix(l.input[l.pos:], tagsDivider) {
l.emit(itemTagName)
return lexTagsDivider
}
if strings.HasPrefix(l.input[l.pos:], tagsRightMeta) {
l.emit(itemTagName)
return lexTagsRightMeta
}
r := l.next()
if r == eof {
break
}
}
l.emit(itemEOF)
return nil
}
func lexTagsDivider(l *lexer) stateFn {
l.pos++
l.emit(itemTagsDivider)
return lexTagName
}
func lexTagsRightMeta(l *lexer) stateFn {
l.pos++
l.emit(itemTagsRightMeta)
return nil
}